


SD.NEXTを使って感じていた事
前回お伝えしたとおり、私は既にSD.NEXTを導入しており、ローカル画像生成AI自体は以前から触っていました。
ただ、SD.NEXTはかなり高機能な反面、設定項目も多く、正直「癖が強いな…」と思う場面も結構あります。
もちろん、細かな調整ができるのは魅力です。Youtube用のアハ画像を作る時など、一部分だけを変化させるインペイント機能にはかなり助けられました。
さらに設定次第で、元画像の雰囲気を少し変える程度から、“もう別画像では?”というレベルまで大胆に変化させる事も可能。こういった細かな調整ができるのも、ローカル画像生成AIの面白いところです。
ただ、普段使いとなると少し話は別。
ChatGPTやNanobananaのような「とりあえずプロンプトを入れれば、それっぽい画像がすぐ出てくる」という手軽さに慣れてしまうと、SD.NEXTはどうしても“作業感”があります。
設定を触り始めると楽しいのですが、「ちょっと1枚作りたい」という時には少し気合いが必要でした。

なぜAUTOMATIC1111を選んだのか
そんな中、最近よく見かけるようになったのが「AUTOMATIC1111」。
画像生成AI界隈ではかなり有名な存在で、解説記事や拡張機能も非常に多い印象です。
さらに最近はIntel GPU環境でも動作情報を見かける機会が増えてきました。
少し前までは、Intel GPUユーザーのローカル画像生成AI環境といえば、実質SD.NEXTぐらいしか選択肢がない印象だったので、これはかなり気になります。
最近はComfyUIなど、かなり本格的な環境も人気ですが、ノードベースの画面はかなり本格的。自由度は高そうなのですが、まず最初に触るには少しハードルが高そうに感じました。
その点AUTOMATIC1111は、情報量が圧倒的に多く、利用者も非常に多い定番環境。
「まず触ってみる」という入口としてかなり安心感があります。
という事で今回は、実際にAUTOMATIC1111を導入してみる事にしました。
まず最初に必要なソフト類
私の環境では以前SD.NEXTを導入していたため、一部ソフトは既に入っていました。
ただ、この記事では「これから初めて導入する人向け」に、必要なものを最初からまとめておきます。
今回必要だったのは主にこのあたり。
- Python
- Git
- AUTOMATIC1111本体
- 画像生成モデル(checkpoint)
画像生成AI界隈は専門用語がかなり多いので、最初は少し圧倒されるかもしれません。
私も最初は、
「モデルって何?」
「checkpointって何?」
「LoRA?」
という状態でした(笑)
ただ、最初はそこまで深く理解しなくても大丈夫。
「画像生成AI本体」と「画像生成用モデル」が必要。
まずはそのぐらいの理解で問題ありません。
Pythonをインストール
まず必要になるのがPython。
AUTOMATIC1111はPython上で動作するため、まずはこちらをインストールします。
ここで私、最初やらかしました。
普通に「次へ」を連打してインストールしたのですが、起動時にエラー。
原因は…。
✅ 「Add Python to PATH」
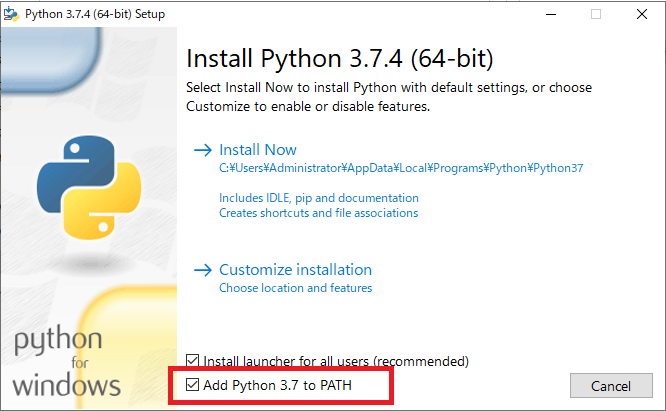
これにチェックを入れ忘れていました。
正直、
「PATHって何?」
状態だったのですが、ここを忘れると後からかなり面倒です。
結果的にPythonを入れ直す事になったので、これから導入する人は最初にチェックを入れておくのがおすすめです。
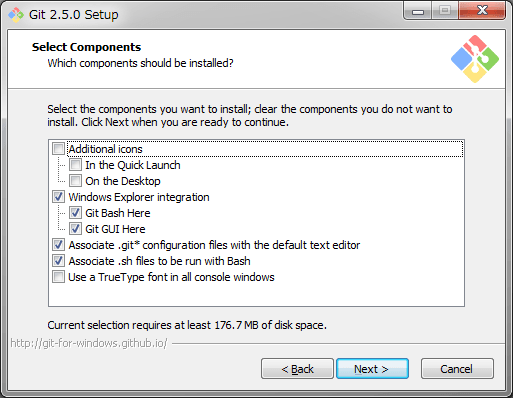
Gitをインストール
次にGitをインストール。
こちらは基本的にデフォルト設定のままで、次へをポチポチするだけでOKでした。
Gitというと難しそうに聞こえますが、今回は「AUTOMATIC1111本体をダウンロードするために使うもの」ぐらいの理解で問題ありません。
AUTOMATIC1111本体をダウンロード
必要ソフトが入ったら、次はAUTOMATIC1111本体を取得します。
GitHubからZIPをダウンロードしても良いのですが、今回はアップデートもしやすそうだったのでGit Cloneで導入しました。
コマンドプロンプトを開き、以下を実行します。
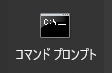
↓
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
しばらく待つと、「stable-diffusion-webui」というフォルダが作成されます。
モデルファイルを準備
ここで少し初心者が混乱しやすいポイント。
AUTOMATIC1111は、本体だけでは画像生成できません。
別途「画像生成モデル」が必要になります。
よく見る「checkpoint」という単語も、この画像生成モデルの事だと思えば大丈夫です。
今回はテスト用として、比較的軽量なモデルを使用しました。
ダウンロードしたモデルファイル(.safetensorsなど)を、以下フォルダへコピーします。
stable-diffusion-webui\models\Stable-diffusion
最初は、
- checkpoint
- LoRA
- VAE
- embedding
- ControlNet
など、聞き慣れない単語が大量に出てきてかなり混乱しました。
ただ、最初から全部理解しようとすると逆に疲れます。
私も最初は、
「本体とモデルがあれば、とりあえず動く」
ぐらいの理解で始めました。
実際、触りながら少しずつ覚えていく感じでも十分でした。
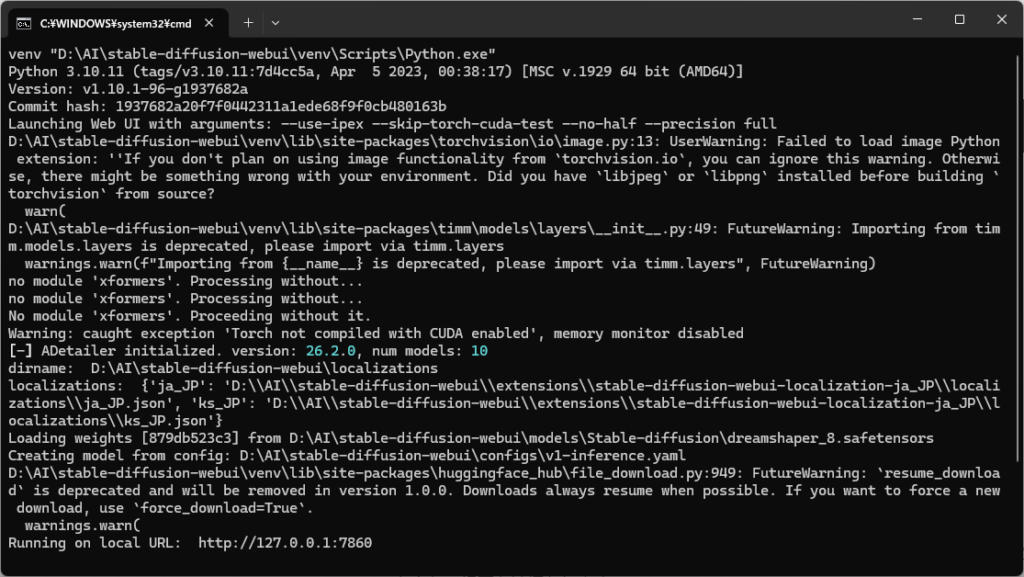
起動してみる
準備ができたら、
webui-user.bat
を実行します。
初回起動時は必要ライブラリを自動ダウンロードするため、かなり時間がかかります。
私の環境でも、
「これ、本当に進んでる?」
と不安になるぐらい黒画面のまま待つ時間がありました(笑)
特に初回は各種インストールが実行される為、起動までかなり時間が掛かります。2回目以降早いです。
特に画像生成AI界隈はNVIDIA環境前提の情報がかなり多いため、Intel GPU環境だと「この設定どこ?」となる場面も結構あります。
ただ最近は対応もかなり進んでおり、以前よりは導入しやすくなっている印象でした。
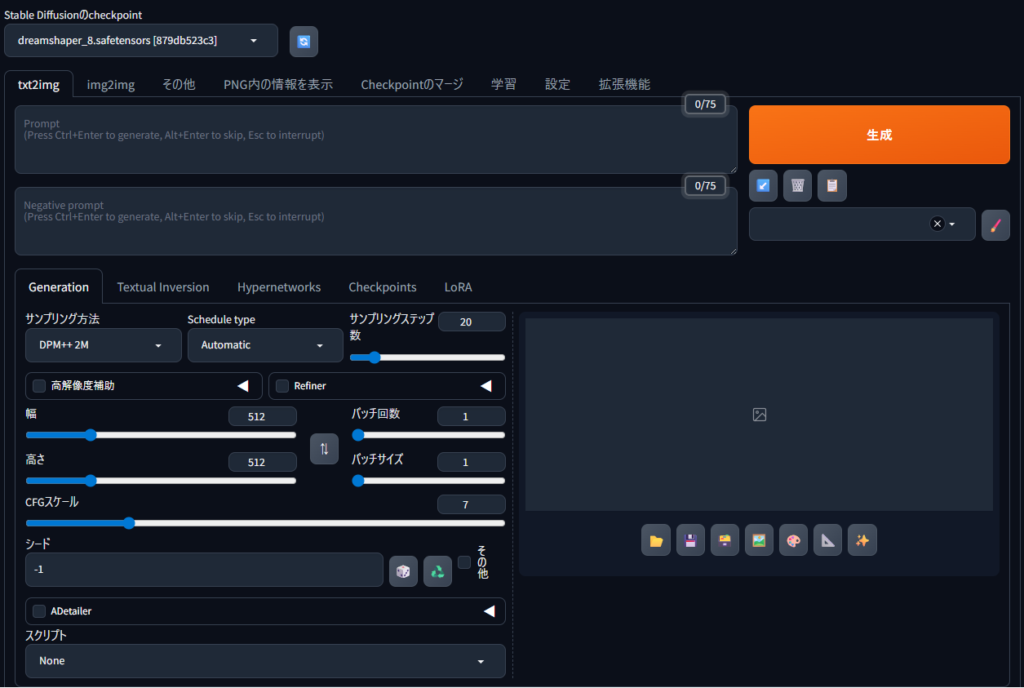
起動完了!最初に思った事
しばらく待つと、ブラウザにAUTOMATIC1111の画面が表示されます。
そして最初に思った感想。
「思ったより普通!」
もっと専門的で難しい画面を想像していたのですが、実際はかなりシンプル。
プロンプト入力欄、Generateボタン、基本設定など、必要なものが分かりやすくまとまっています。
むしろChatGPTやNanobananaのようなWeb系画像生成AIを使っていた人ほど、「あ、これなら分かるかも」と感じるかもしれません。
以前使っていたSD.NEXTはかなり高機能でしたが、その分、設定項目の多さに圧倒される部分もありました。
一方AUTOMATIC1111は、「まず画像生成してみる」までが非常にシンプル。
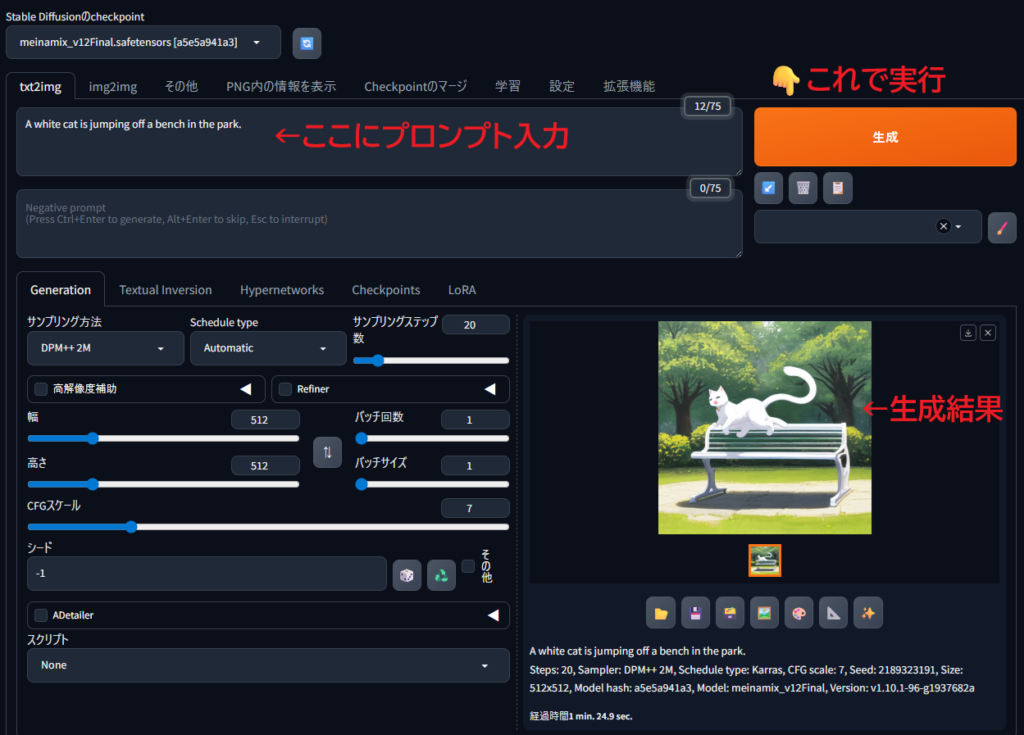
世界中で利用者が多い理由も、少し分かった気がしました。
次回、実際に画像生成してみる
という事で、無事AUTOMATIC1111の導入完了。
次回は、実際に画像生成してみた感想や、ChatGPT・Nanobanana・SD.NEXTとの違いを見ながら、ファーストレビューを書いていこうと思います。

コメント